使用 torchtext 库进行文本分类 ¶
项目地址:https://pytorch.apachecn.org/2.0/tutorials/beginner/text_sentiment_ngrams_tutorial
原始地址:https://pytorch.org/tutorials/beginner/text_sentiment_ngrams_tutorial.html
在本教程中,我们将展示如何使用 torchtext 库构建用于文本分类分析的数据集。用户可以灵活地
- 作为迭代器访问原始数据
- 构建数据处理管道,将原始文本字符串转换为
torch.Tensor可用于训练模型 - 使用torch.utils.data.DataLoader
先决条件 ¶
在运行本教程之前,需要安装最新 2.x 版本的 portalocker 软件包。例如,在 Colab 环境中,可以通过在顶部添加以下行来完成脚本:
访问原始数据集迭代器 ¶
torchtext 库提供了一些原始数据集迭代器,可生成原始文本字符串。例如, AG_NEWS 数据集迭代器生成作为标签和文本元组形式的原始数据。
要访问 torchtext 数据集,请按照以下位置的说明安装 torchdata https://github.com/pytorch/data 。
输出:
next(train_iter)
>>> (3, "Fears for T N pension after talks Unions representing workers at Turner
Newall say they are 'disappointed' after talks with stricken parent firm Federal
Mogul.")
next(train_iter)
>>> (4, "The Race is On: Second Private Team Sets Launch Date for Human
Spaceflight (SPACE.com) SPACE.com - TORONTO, Canada -- A second\\team of
rocketeers competing for the #36;10 million Ansari X Prize, a contest
for\\privately funded suborbital space flight, has officially announced
the first\\launch date for its manned rocket.")
next(train_iter)
>>> (4, 'Ky. Company Wins Grant to Study Peptides (AP) AP - A company founded
by a chemistry researcher at the University of Louisville won a grant to develop
a method of producing better peptides, which are short chains of amino acids, the
building blocks of proteins.')
准备数据处理管道 ¶
我们重新审视了 torchtext 库的非常基本的组件,包括词汇、词向量、分词器。这些是原始文本字符串的基本数据处理构建块。
这是使用分词器和词汇进行典型 NLP 数据处理的示例。第一步是使用原始训练数据集构建词汇表。这里我们使用内置工厂函数build_vocab_from_iterator 接受生成列表或标记迭代器的迭代器。用户还可以传递要添加到词汇表中的任何特殊符号。
from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator
tokenizer = get_tokenizer("basic_english")
train_iter = AG_NEWS(split="train")
def yield_tokens(data_iter):
for _, text in data_iter:
yield tokenizer(text)
vocab = build_vocab_from_iterator(yield_tokens(train_iter), specials=["<unk>"])
vocab.set_default_index(vocab["<unk>"])
词汇块将标记列表转换为整数。
使用分词器和词汇表准备文本处理管道。文本和标签管道将用于处理来自数据集迭代器的原始数据字符串。
文本管道根据词汇表中定义的查找表将文本字符串转换为整数列表。标签管道将标签转换为整数。例如,
生成数据批次和迭代器 ¶
torch.utils.data.DataLoader 建议 PyTorch 用户使用(教程是此处 )。它适用于实现getitem()和的地图样式数据集n len()协议,表示从索引/键到数据样本的映射。它还适用于 shuffle 参数为False的可迭代数据集。
在发送到模型之前, collate_fn函数会处理从 DataLoader生成的一批样本。 collate_fn的输入是一批数据,其批量大小为 DataLoader,collate_fn.根据数据处理管道对其进行处理之前声明过。请注意此处并确保collate_fn 被声明为顶级定义。这可确保该函数在每个工作线程中都可用。
在此示例中,原始数据批量输入中的文本条目被打包到一个列表中,并连接为单个tensor,用于
nn.EmbeddingBag的输入。偏移量是分隔符tensor,表示文本tensor中各个序列的起始索引。标签是一个tensor,保存各个文本条目的标签。
from torch.utils.data import DataLoader
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def collate_batch(batch):
label_list, text_list, offsets = [], [], [0]
for _label, _text in batch:
label_list.append(label_pipeline(_label))
processed_text = torch.tensor(text_pipeline(_text), dtype=torch.int64)
text_list.append(processed_text)
offsets.append(processed_text.size(0))
label_list = torch.tensor(label_list, dtype=torch.int64)
offsets = torch.tensor(offsets[:-1]).cumsum(dim=0)
text_list = torch.cat(text_list)
return label_list.to(device), text_list.to(device), offsets.to(device)
train_iter = AG_NEWS(split="train")
dataloader = DataLoader(
train_iter, batch_size=8, shuffle=False, collate_fn=collate_batch
)
定义模型 ¶
该模型由 nn.EmbeddingBag 层加上一个线性层组成分类目的。 nn.EmbeddingBag 默认模式为 “mean” 计算 “bag” 嵌入的平均值。尽管此处的文本条目具有不同的长度, nn.EmbeddingBag 模块不需要此处填充,因为文本长度保存在偏移量中。
此外,由于 nn.EmbeddingBag 会动态累积嵌入的平均值, nn.EmbeddingBag 可以提高处理tensor序列的性能和内存效率。
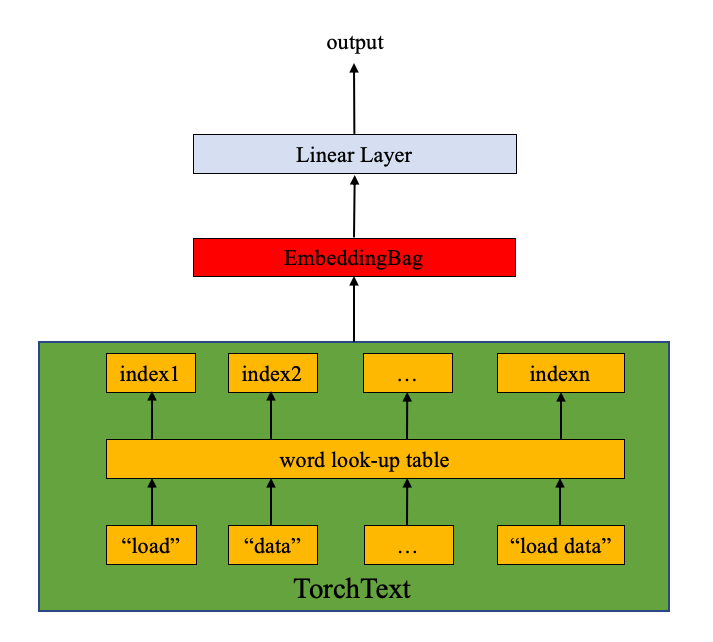
from torch import nn
class TextClassificationModel(nn.Module):
def __init__(self, vocab_size, embed_dim, num_class):
super(TextClassificationModel, self).__init__()
self.embedding = nn.EmbeddingBag(vocab_size, embed_dim, sparse=False)
self.fc = nn.Linear(embed_dim, num_class)
self.init_weights()
def init_weights(self):
initrange = 0.5
self.embedding.weight.data.uniform_(-initrange, initrange)
self.fc.weight.data.uniform_(-initrange, initrange)
self.fc.bias.data.zero_()
def forward(self, text, offsets):
embedded = self.embedding(text, offsets)
return self.fc(embedded)
启动实例 ¶
AG_NEWS 数据集有四个标签,因此类别数为四个。
我们构建一个嵌入维度为 64 的模型。词汇大小等于词汇实例的长度。类的数量等于标签的数量,
train_iter = AG_NEWS(split="train")
num_class = len(set([label for (label, text) in train_iter]))
vocab_size = len(vocab)
emsize = 64
model = TextClassificationModel(vocab_size, emsize, num_class).to(device)
定义函数来训练模型并评估结果。 ¶
import time
def train(dataloader):
model.train()
total_acc, total_count = 0, 0
log_interval = 500
start_time = time.time()
for idx, (label, text, offsets) in enumerate(dataloader):
optimizer.zero_grad()
predicted_label = model(text, offsets)
loss = criterion(predicted_label, label)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 0.1)
optimizer.step()
total_acc += (predicted_label.argmax(1) == label).sum().item()
total_count += label.size(0)
if idx % log_interval == 0 and idx > 0:
elapsed = time.time() - start_time
print(
"| epoch {:3d} | {:5d}/{:5d} batches "
"| accuracy {:8.3f}".format(
epoch, idx, len(dataloader), total_acc / total_count
)
)
total_acc, total_count = 0, 0
start_time = time.time()
def evaluate(dataloader):
model.eval()
total_acc, total_count = 0, 0
with torch.no_grad():
for idx, (label, text, offsets) in enumerate(dataloader):
predicted_label = model(text, offsets)
loss = criterion(predicted_label, label)
total_acc += (predicted_label.argmax(1) == label).sum().item()
total_count += label.size(0)
return total_acc / total_count
拆分数据集并运行模型 ¶
由于原始 AG_NEWS 没有有效数据集,因此我们将训练数据集分为训练集/有效集,分割比为 0.95(训练)和0.05(有效)。这里我们使用 torch.utils.data.dataset.random_split PyTorch 核心库中的函数。
CrossEntropyLoss 标准结合 nn.LogSoftmax()
和 nn.NLLLoss() 在单个类中。在使用 C 类训练分类问题时非常有用。 SGD 实现随机梯度下降法作为优化器。初始
学习率设置为5.0。 StepLR 此处用于调整学习率历经纪元。
from torch.utils.data.dataset import random_split
from torchtext.data.functional import to_map_style_dataset
# Hyperparameters
EPOCHS = 10 # epoch
LR = 5 # learning rate
BATCH_SIZE = 64 # batch size for training
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=LR)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1.0, gamma=0.1)
total_accu = None
train_iter, test_iter = AG_NEWS()
train_dataset = to_map_style_dataset(train_iter)
test_dataset = to_map_style_dataset(test_iter)
num_train = int(len(train_dataset) * 0.95)
split_train_, split_valid_ = random_split(
train_dataset, [num_train, len(train_dataset) - num_train]
)
train_dataloader = DataLoader(
split_train_, batch_size=BATCH_SIZE, shuffle=True, collate_fn=collate_batch
)
valid_dataloader = DataLoader(
split_valid_, batch_size=BATCH_SIZE, shuffle=True, collate_fn=collate_batch
)
test_dataloader = DataLoader(
test_dataset, batch_size=BATCH_SIZE, shuffle=True, collate_fn=collate_batch
)
for epoch in range(1, EPOCHS + 1):
epoch_start_time = time.time()
train(train_dataloader)
accu_val = evaluate(valid_dataloader)
if total_accu is not None and total_accu > accu_val:
scheduler.step()
else:
total_accu = accu_val
print("-" * 59)
print(
"| end of epoch {:3d} | time: {:5.2f}s | "
"valid accuracy {:8.3f} ".format(
epoch, time.time() - epoch_start_time, accu_val
)
)
print("-" * 59)
输出:
| epoch 1 | 500/ 1782 batches | accuracy 0.694
| epoch 1 | 1000/ 1782 batches | accuracy 0.856
| epoch 1 | 1500/ 1782 batches | accuracy 0.877
-----------------------------------------------------------
| end of epoch 1 | time: 11.00s | valid accuracy 0.886
-----------------------------------------------------------
| epoch 2 | 500/ 1782 batches | accuracy 0.898
| epoch 2 | 1000/ 1782 batches | accuracy 0.899
| epoch 2 | 1500/ 1782 batches | accuracy 0.906
-----------------------------------------------------------
| end of epoch 2 | time: 10.60s | valid accuracy 0.895
-----------------------------------------------------------
| epoch 3 | 500/ 1782 batches | accuracy 0.916
| epoch 3 | 1000/ 1782 batches | accuracy 0.913
| epoch 3 | 1500/ 1782 batches | accuracy 0.915
-----------------------------------------------------------
| end of epoch 3 | time: 10.63s | valid accuracy 0.894
-----------------------------------------------------------
| epoch 4 | 500/ 1782 batches | accuracy 0.930
| epoch 4 | 1000/ 1782 batches | accuracy 0.932
| epoch 4 | 1500/ 1782 batches | accuracy 0.929
-----------------------------------------------------------
| end of epoch 4 | time: 10.61s | valid accuracy 0.902
-----------------------------------------------------------
| epoch 5 | 500/ 1782 batches | accuracy 0.932
| epoch 5 | 1000/ 1782 batches | accuracy 0.933
| epoch 5 | 1500/ 1782 batches | accuracy 0.931
-----------------------------------------------------------
| end of epoch 5 | time: 10.59s | valid accuracy 0.902
-----------------------------------------------------------
| epoch 6 | 500/ 1782 batches | accuracy 0.933
| epoch 6 | 1000/ 1782 batches | accuracy 0.932
| epoch 6 | 1500/ 1782 batches | accuracy 0.935
-----------------------------------------------------------
| end of epoch 6 | time: 10.57s | valid accuracy 0.903
-----------------------------------------------------------
| epoch 7 | 500/ 1782 batches | accuracy 0.934
| epoch 7 | 1000/ 1782 batches | accuracy 0.933
| epoch 7 | 1500/ 1782 batches | accuracy 0.935
-----------------------------------------------------------
| end of epoch 7 | time: 10.56s | valid accuracy 0.903
-----------------------------------------------------------
| epoch 8 | 500/ 1782 batches | accuracy 0.935
| epoch 8 | 1000/ 1782 batches | accuracy 0.933
| epoch 8 | 1500/ 1782 batches | accuracy 0.935
-----------------------------------------------------------
| end of epoch 8 | time: 10.59s | valid accuracy 0.904
-----------------------------------------------------------
| epoch 9 | 500/ 1782 batches | accuracy 0.934
| epoch 9 | 1000/ 1782 batches | accuracy 0.934
| epoch 9 | 1500/ 1782 batches | accuracy 0.934
-----------------------------------------------------------
| end of epoch 9 | time: 10.63s | valid accuracy 0.904
-----------------------------------------------------------
| epoch 10 | 500/ 1782 batches | accuracy 0.934
| epoch 10 | 1000/ 1782 batches | accuracy 0.936
| epoch 10 | 1500/ 1782 batches | accuracy 0.933
-----------------------------------------------------------
| end of epoch 10 | time: 10.62s | valid accuracy 0.905
-----------------------------------------------------------
使用测试数据集评估模型 ¶
检查测试数据集的结果…
print("Checking the results of test dataset.")
accu_test = evaluate(test_dataloader)
print("test accuracy {:8.3f}".format(accu_test))
输出:
对随机新闻进行测试 ¶
使用迄今为止最好的模型并测试高尔夫新闻。
ag_news_label = {1: "World", 2: "Sports", 3: "Business", 4: "Sci/Tec"}
def predict(text, text_pipeline):
with torch.no_grad():
text = torch.tensor(text_pipeline(text))
output = model(text, torch.tensor([0]))
return output.argmax(1).item() + 1
ex_text_str = "MEMPHIS, Tenn. – Four days ago, Jon Rahm was \
enduring the season’s worst weather conditions on Sunday at The \
Open on his way to a closing 75 at Royal Portrush, which \
considering the wind and the rain was a respectable showing. \
Thursday’s first round at the WGC-FedEx St. Jude Invitational \
was another story. With temperatures in the mid-80s and hardly any \
wind, the Spaniard was 13 strokes better in a flawless round. \
Thanks to his best putting performance on the PGA Tour, Rahm \
finished with an 8-under 62 for a three-stroke lead, which \
was even more impressive considering he’d never played the \
front nine at TPC Southwind."
model = model.to("cpu")
print("This is a %s news" % ag_news_label[predict(ex_text_str, text_pipeline)])
输出:
脚本总运行时间: ( 1 分 58.358 秒)
