音频数据集 ¶
译者:龙琰
项目地址:https://pytorch.apachecn.org/2.0/tutorials/beginner/audio_datasets_tutorial
原始地址:https://docs.pytorch.org/audio/stable/tutorials/audio_datasets_tutorial.html
Author: Moto Hira
torchaudio 提供了对公共可访问数据集的轻松访问。有关可用数据集的列表,请参阅官方文档。
输出:
import os
import IPython
import matplotlib.pyplot as plt
_SAMPLE_DIR = "_assets"
YESNO_DATASET_PATH = os.path.join(_SAMPLE_DIR, "yes_no")
os.makedirs(YESNO_DATASET_PATH, exist_ok=True)
def plot_specgram(waveform, sample_rate, title="Spectrogram"):
waveform = waveform.numpy()
figure, ax = plt.subplots()
ax.specgram(waveform[0], Fs=sample_rate)
figure.suptitle(title)
figure.tight_layout()
在这里,我们展示了如何使用 torchaudio.dataset.YESNO数据集。
输出:
2.8%
5.6%
8.4%
11.1%
13.9%
16.7%
19.5%
22.3%
25.1%
27.9%
30.7%
33.4%
36.2%
39.0%
41.8%
44.6%
47.4%
50.2%
52.9%
55.7%
58.5%
61.3%
64.1%
66.9%
69.7%
72.5%
75.2%
78.0%
80.8%
83.6%
86.4%
89.2%
92.0%
94.7%
97.5%
100.0%
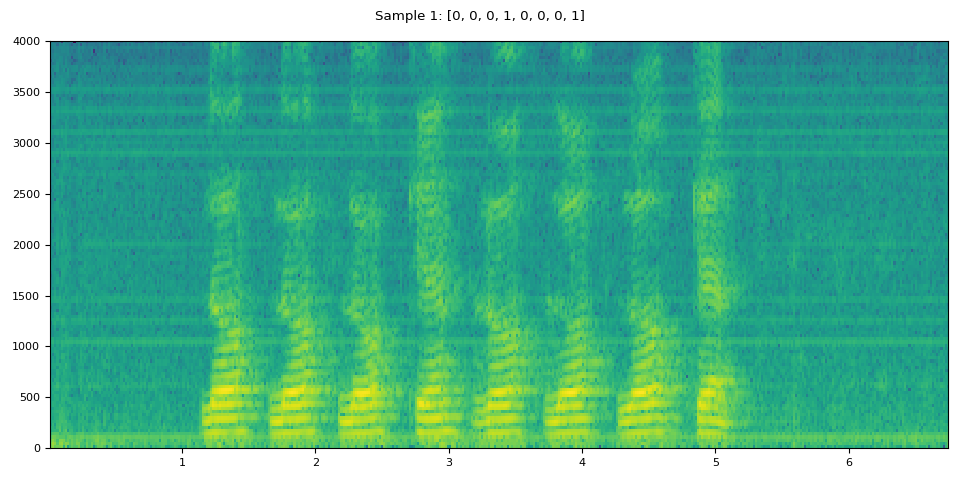
i = 1
waveform, sample_rate, label = dataset[i]
plot_specgram(waveform, sample_rate, title=f"Sample {i}: {label}")
IPython.display.Audio(waveform, rate=sample_rate)
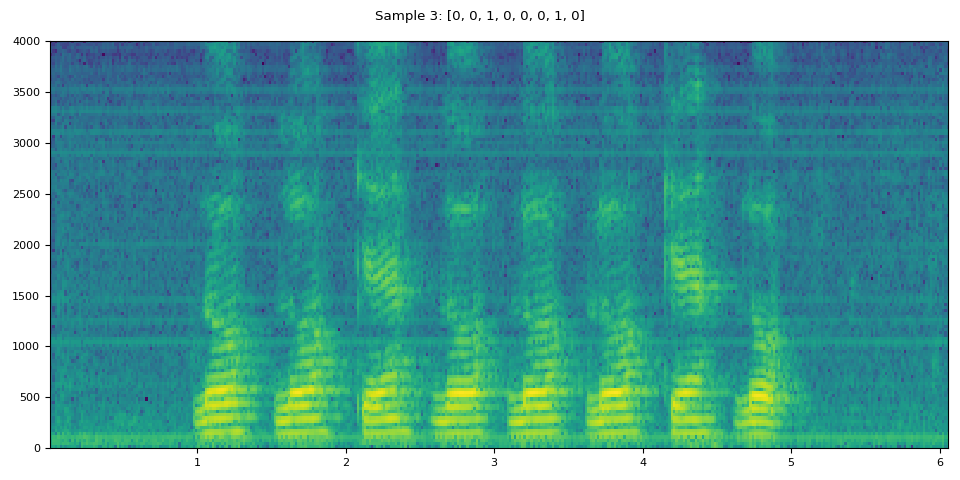
i = 3
waveform, sample_rate, label = dataset[i]
plot_specgram(waveform, sample_rate, title=f"Sample {i}: {label}")
IPython.display.Audio(waveform, rate=sample_rate)
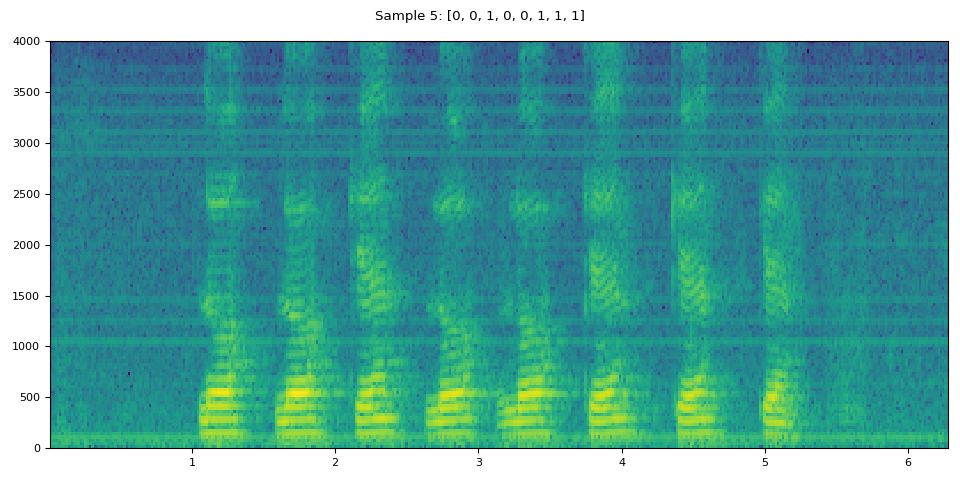
i = 5
waveform, sample_rate, label = dataset[i]
plot_specgram(waveform, sample_rate, title=f"Sample {i}: {label}")
IPython.display.Audio(waveform, rate=sample_rate)
脚本的总运行时间:(0分钟3.295秒)
